
Learning how to optimize DAX measures is an essential skill for improving slow-running reports. We can use DAX Studio to help us understand how our DAX measure is translated into code that can retrieve the data for us, and it gets pretty complex.
A summary of the steps for executing a Power BI report measure loaded in a report to return the data is in the table below. Power BI and tools like Tabular Editor and DAX Studio communicate with the tabular model in the Power BI service via the XMLA endpoints. DAX expressions for creating measures can be created in PBI Desktop, PBI Service, and Tabular Editor. A DAX query can be created and edited in the DAX Query tab of the PBI client and DAX Studio. The human-readable internal query plan and xmsQL can be viewed in DAX Studio. Direct queries SQL can be created in the PBI desktop client or connected directly to tables or views in an SQL database. SQL Server profile can be used to trace commands sent to the tabular model and every XMLA query the engine generates behind the scenes.
Using DAX Studio, we can analyse the query plans made by the Formula Engine (FE) to look for issues that may slow the query. Using the server timings tab, we can look at the xmSQL steps to understand where the time is spent by the storage engine (SE) in data retrieval.
Data Retrieval Steps – knowledge to Optimize DAX Measures
| Step | Processor | Code | Description |
| 1. Report visual with DAX Measure loads the DAX Expression | Power BI Report | DAX Expression (Measure) | A visual containing a DAX measure triggers a data request when it loads or refreshes. The measures DAX expression is stored in the model metadata. |
| 2. The DAX expression is converted to a DAX Query | Power BI Client / Query Generator | DAX Query | DAX Query |
| 3. DAX Query sent via XMLA to Tabular engine | XMLA Protocol Layer | XMLA Command | The client sends the DAX query inside XMLA statement to the Analysis Services (Tabular) Engine. |
| 4. Formula engine parses and builds the query plan | Formula Engine (in Tabular engine) | Internal query pan (can view in DAX studio, but code is C++ internal) | The FE parses, validates, and creates an internal query plan (DAX query execution plan) |
| 5. The Formula engine requests data retrieval from the storage engine | Storage engine (Vertipaq Storage Engine or Direct Query Storage Engine (e.g., SQL Server) | SE executes compressed scans, filter, and group operations, and returns the results to the FE | FE delegates data scanning and aggregations to the storage engine (import, DirectQuery or composite) |
| 6. The storage engine executes and returns results to FE | Vertipaq Database or external SQL database, e.g., SQL Server | xmSQL (Vertipq) / SQL query (DirectQuery) | SE executes columnar scans, filter, and group operations, and returns the results to the FE |
| 7. Formula Engine performs any final calculations | Formula Engine (FE) | Tabular result (via XMLA response) | The FE completes all non-foldable DAX logic (e.g., iterators, context transactions, SUMX, FILTER) using results returned from the SE. |
| 8. Final result returned and rendered in the visual | Power BI Client | Tabular result (via XMLA reponse) | Tabular result (via XMLA response) |
Test 1: A Simple DAX measure
DAX Expression (Created in Power BI Desktop)
Fare Amount = SUM(tlc_green_trips_2016[fare_amount])
DAX Query (DAX Studio)
DEFINE
—- MODEL MEASURES BEGIN —-
MEASURE _Measures[Fare Amount] = SUM(tlc_green_trips_2016[fare_amount])
—- MODEL MEASURES END —
DAX Query that returns Result (one row, one column)
EVALUATE
{ [Fare Amount] }
DAX Query that returns a result for a table /visual
EVALUATE
SUMMARIZECOLUMNS(
DimZone[Zone_id],
“Fare”, [Fare Amount]
)
Query Plan (DAX Studio)
The query plan is created by the Formula engine. We can use the query plan to help us optimize DAX measures.
There are 2 plans:
1. Logical Query Plan – What needs to be computed. Conceptual level – FE only – DAX operations: Calculate, Filter, Sum
2. Physical Query Plan – How to compute (created by FE and SE cooperation) – Internal operations, e.g, Scan_vertipaq, SPool, GroupBy, CrossApply)
Download DAX Studio here
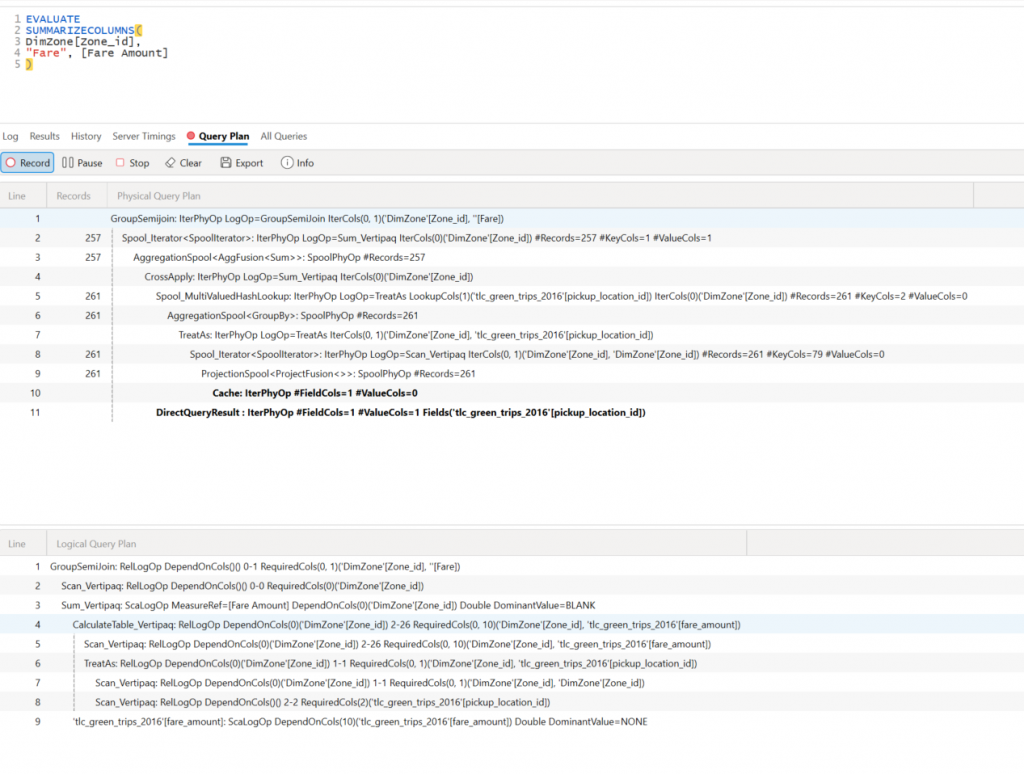
Things to look out for in the query plan are as follows:
1. Iterator nodes (e.g., FilterIterator, SumXIterator) that are slow, row-by-row calculations (FE bound).
2. CallbackDataID: Commands by SE back to FE (which can cause a major slowdown.
3. NonEmpty or CrossJoin nodes on large tables: Cartesian joins are dangerous and can slow large models.
Good things are:
1. Scan_Vertipaq and Sum_Vertipaq show aggregation done in SE
2. GroupBy and AggregationSpool show grouping done by SE
3. TREATAS and CALCULATETABLE – relationship filtering applied efficiently.
So we see in the above example the use of Scan_Vertipaq and Sum_Vertipaq, CALCULATETABLE, and TREATAS
And we can’t see any of the bad points that could slow down the query.
xmSQL (DAX Studio (Server Timings)
Inspecting xmSQL in DAX Studio to Optimize DAX Measures
The storage engine activity is logged in the server timings tab of DAX Studio. The request is broken down into 2 steps plus the metrics:
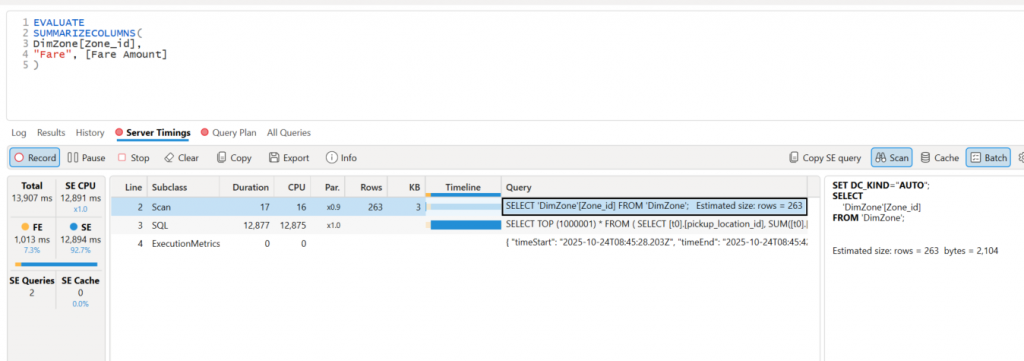
The steps are as follows:
1. Scan –
SET DC_KIND=”AUTO”; — how to set the data cache
SELECT
‘DimZone'[Zone_id] —Selects the columns to group by for the next step to use as keys.
FROM ‘DimZone’;
Estimated size: rows = 263 bytes = 2,104
2. Then the next step does the work. It uses the results from the first scan in the WHERE clause.
Note the N in N’60’ is NVARCHAR.
WHERE (NOT (([a0] IS NULL))) — allows for entries not in the zoneid list in the first scan.
The SELECT is limited to return 1M rows as default safety in xmSQL..
Note: Grouping and SUM are done in the SE, not the FE – so this is good as SE is faster than the FE (which is single threaded)
The relationship (Zone_ID) is correctly folded as seen in the IN(…)
SELECT TOP (1000001) *
FROM (
SELECT [t0].[pickup_location_id],
SUM([t0].[fare_amount]) AS [a0]
FROM [tlc_green_trips_2016] AS [t0]
WHERE (
(
[t0].[pickup_location_id] IN (
N’60’,
N’27’,
N’202′,
N’185′,
N’101′,
N’258′,
…….
N’236′,
N’44’
)
)
OR ([t0].[pickup_location_id] IS NULL)
)
GROUP BY [t0].[pickup_location_id]
) AS [MainTable]
WHERE (NOT (([a0] IS NULL)))
So to summarise, the Vertipaq query looks good. The heavy work of filtering and grouping is done by the storage engine, so the query is folding correctly and being passed back to the FE to do the work. Understanding these steps is essential in order to optimize DAX measures.
Here is another post on analysing Analyzing DAX Server Timings in DAX Studio