
The DISTINCTCOUNT() function can slow down reports, but if it’s required, then what are the alternatives?
Here we test DISTINCTCOUNT DAX speed against other DAX Options.
Test 1: Adventure Works
-- Method 1: DISTINCTCOUNT()
Customers = DISTINCTCOUNT('FactInternetSales'[CustomerKey])
-- Method 2: COUNTROWS(VALUES()
Customers2 = COUNTROWS(VALUES('FactInternetSales'[CustomerKey]))
-- Method 3: SUMX()
Customers3 = SUMX(VALUES('FactInternetSales'[CustomerKey]), 1)
The measures all give the same results, but which one is faster?
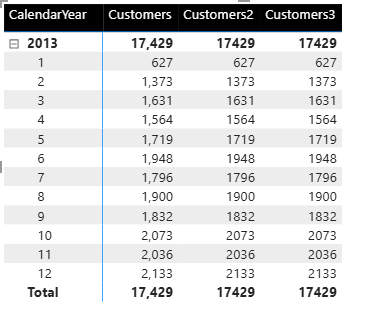
We can test these measures by opening the above matrix for all years to give us a bit more data. The results are too close to call, so we need more data to work with.
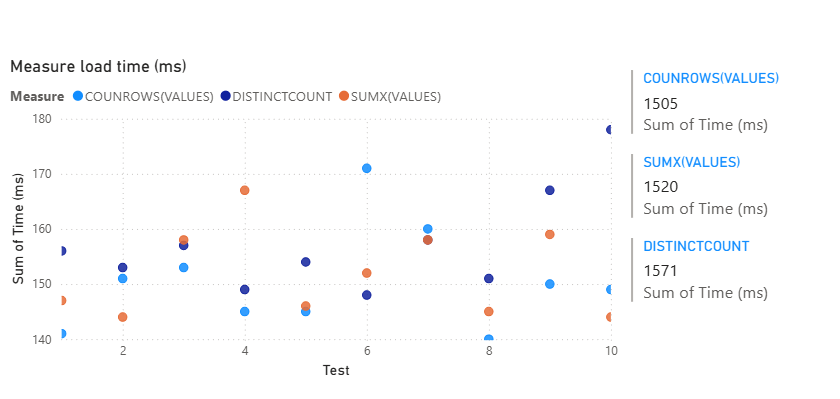
Test 2: Contoso Database:
The FactOnlineSales table in the Contoso data warehouse has over 12 million rows of data, which should give our unique count measures a better run.
We use the same measure calculations but in the new table as follows:
CTSO Customers = DISTINCTCOUNT('FactOnlineSales'[CustomerKey])
CTSO Customers2 = COUNTROWS(VALUES('FactOnlineSales'[CustomerKey]))
CTSO Customers3 = SUMX(VALUES('FactOnlineSales'[CustomerKey]), 1)We can then test the speed of the measure using the performance analyzer, and DISTINCTCOUNT distinctly loses!
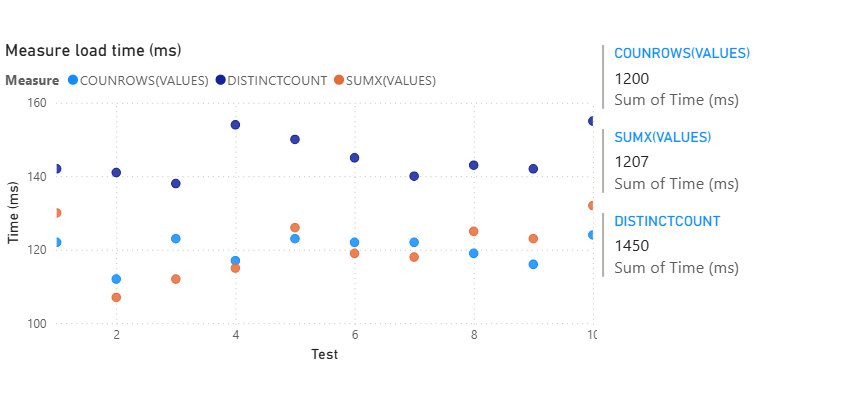
Why is DISTINCTCOUNT() slower in the test results?
The brains as SQL BI have a good article about DISTINCTCOUNT() vs. SUMX, and they refer to using DAX Studio to get into the details of what’s going on with the DAX query.
We can start by using the measure in a simple card visual in Power BI to get the simplest DAX to analyze.
We can copy the code from the performance analyzer into DAX Studio and select the options for getting our output.
1. Clear on run (clears the cache each time on run). Note this is session-based so it won’t clear the whole cache for you dataset.
2. Query plan that relates to the 2 engines: Formula Engine and Storage engine.
There are two query plans generated from a DAX measure:
Formula Engine plan — defines logical steps (filters, joins, iterators).
Storage Engine plan(s) — defines physical scans (which columns, which filters, aggregations).
If the DAX query is simple, it only needs to run the Formula Engine (FE) plan, but there is less information available in DAX Studio. Note that the storage engine is faster than the formula engine at retrieving results.
Engine Memory
| Formula Engine | Memory Type | Description |
|---|
| SE | Persistent, compressed memory (the VertiPaq model) | The actual stored dataset — physical columns and segments |
| FE | Ephemeral, uncompressed memory (working memory) | Virtual tables, intermediate results, cached expressions |
Engine Speed
| Engine | Type of work | Speed | Threads | Data format |
|---|---|---|---|---|
| Storage Engine (SE) | Scanning, filtering, grouping, aggregating | ⚡ Very fast | Multi-threaded | Compressed, columnar |
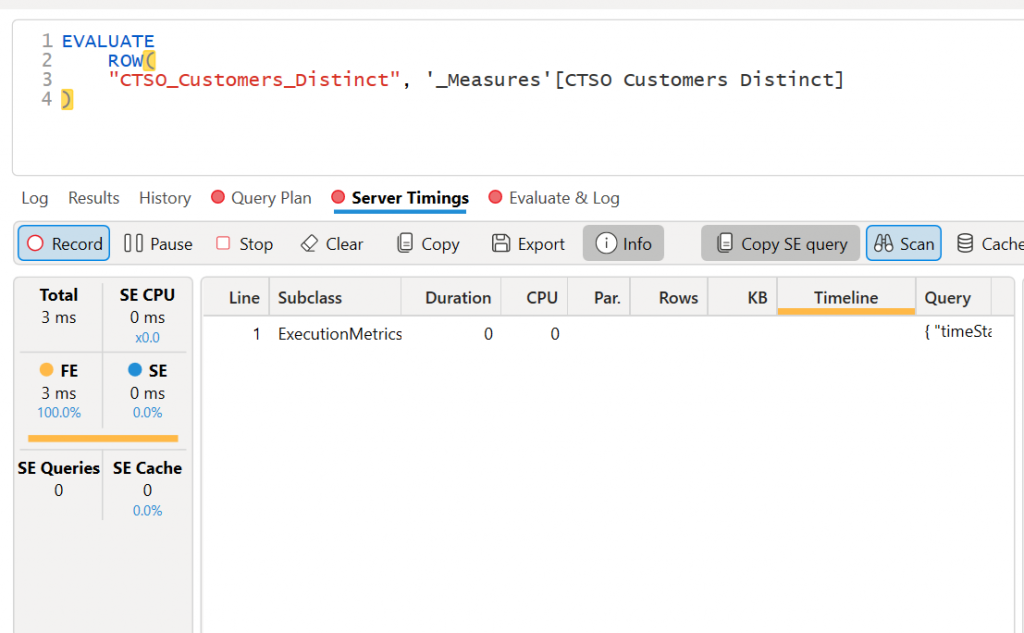
| Formula Engine (FE) | Evaluating DAX expressions, context transitions, row-by-row logic | 🐢 Slower | Single-threaded | Uncompressed, row-based virtual tables |
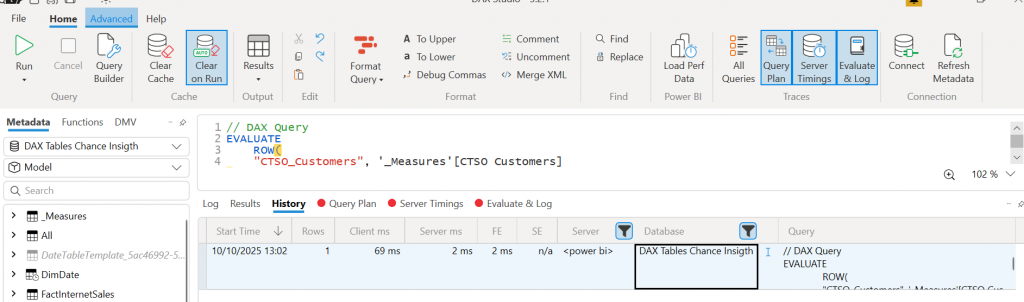
If we look at server timings, we can see there is no time for the SE, so the
For a complete guide to DAX functions, check out the DAX Function Reference